��(d��ng)ǰλ�ã���� > �W(xu��)��(x��)�YԴ > �v������ > ���������cAdam��(y��u)�����ı��^

 ���������cAdam��(y��u)�����ı��^
�r�g��2025-02-20 ��Դ���A���hҊ
���������cAdam��(y��u)�����ı��^
�r�g��2025-02-20 ��Դ���A���hҊ
��(y��u)����(optimizer)
Ŀ��(bi��o): ��С���pʧ����(sh��)
�^�̣� �ڷ��������, ����(j��)�W(xu��)��(x��)��(lr)�팦����(sh��)�M�и��£���K���͓pʧ����(sh��)�Ĵ�С, ʹ����(j��ng)�W(w��ng)�j(lu��)ݔ������(����(sh��)�M�ϵĸ���)

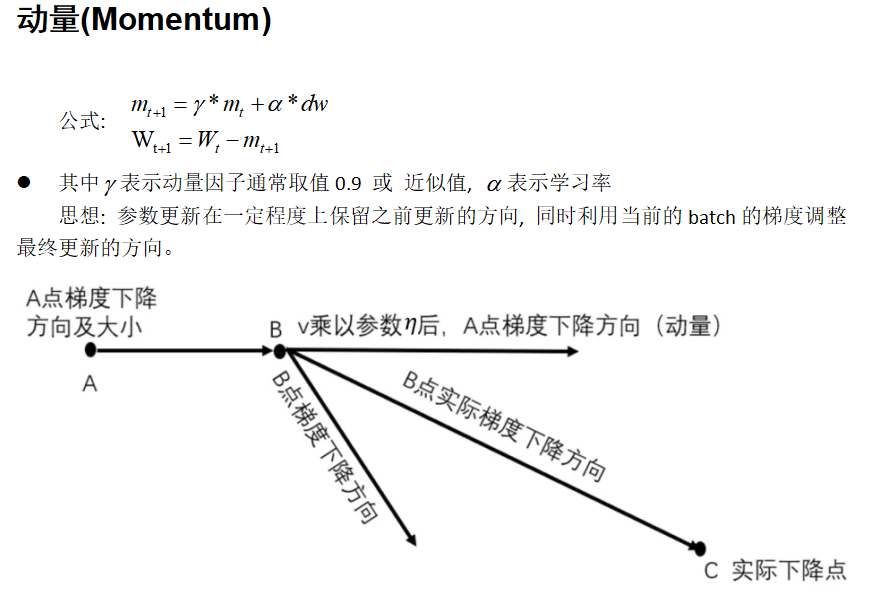
��(y��u)�c:
1. ǰ���ݶ�һ�r�܉���ٌW(xu��)��(x��)
2. ǰ���ݶȲ�һ�r�܉�������ʎ, Խ�^�ֲ���Сֵ
ȱ�c:
1. ����һ���~��ą���(sh��) y

˼��: �Y(ji��)��Momentum��RMSprop�ɷN��(y��u)�������㷨, ������һ�A�ع�Ӌ�Ͷ��A�ع�Ӌ��
��(y��u)�c:
1. Adam�܉��Ԅ��{(di��o)��ÿ������(sh��)�ČW(xu��)��(x��)��, �܉�ܺõ�̎�����ͷ�ƽ��(w��n)��Ӗ(x��n)����(sh��)��(j��)
2. ���^��������׃�W(xu��)��(x��)��(AdaGrad)�ă�(y��u)����, �����Ӗ(x��n)���ٶ�
���Y(ji��)��
�����δ֪ģ�����M��Ӗ(x��n)��, �����ȿ��]ʹ��Adam�_���pʧ����(sh��)�܉��ҵ���Сֵ, ��ģ�͔M�ϵĺ���(sh��)�܉��Ք�,Ȼ���ГQ��SGD�M��Ӗ(x��n)��, �����_������(y��ng)��ֵ��
 �n�̷������A���hҊ(li��n)��NXP�Ƴ�i.MX8M Plus�_�l(f��)�c���`�n�̷���������HarmonyOSϵ�y(t��ng)����(li��n)�W(w��ng)�_�l(f��)����(zh��n)�n�̣��n�̷�����HaaS EDU K1�_�l(f��)�̳̣����n��ҕ�l��Դ�a���°�C�Z�Ծ���֮�����Z��ҕ�l�̳��ذ�ٛ�ͣ�Ƕ��ʽ���rֵ2000Ԫ��Ƕ��ʽ���b�̴̳�Y�����M�ͣ����㶮Ƕ���rֵ1000Ԫ������ARMϵ��ҕ�l������̳����r���t���������¡�ARM�n���n�Ì�䛾��A��ҕ�l���M�I(l��ng)ȡ����(n��i)��Դ linux��(n��i)�˼����c���Ƽ��g(sh��)�A���ԌW(xu��)��(x��)���������cAdam��(y��u)�����ı��^һ���x�����ډ��s��֪�Ĕ�(sh��)��(j��)���s���g(sh��)Ƕ��ʽϵ�y(t��ng)�еĶ��̎�����c����Ӌ��Ƕ��ʽϵ�y(t��ng)�е�Ӳ�����ܼ��������Ɍ����W(w��ng)�j(lu��)��GAN�����g(sh��)����(w��n)�����cģʽ����Ƕ��ʽϵ�y(t��ng)�еĴ��a��(y��u)���c���s���g(sh��)����Ƕ��ʽϵ�y(t��ng)�ĄӑB(t��i)늉��l���{(di��o)����DVFS������ע�����C��:Transformerģ�͵��������
�n�̷������A���hҊ(li��n)��NXP�Ƴ�i.MX8M Plus�_�l(f��)�c���`�n�̷���������HarmonyOSϵ�y(t��ng)����(li��n)�W(w��ng)�_�l(f��)����(zh��n)�n�̣��n�̷�����HaaS EDU K1�_�l(f��)�̳̣����n��ҕ�l��Դ�a���°�C�Z�Ծ���֮�����Z��ҕ�l�̳��ذ�ٛ�ͣ�Ƕ��ʽ���rֵ2000Ԫ��Ƕ��ʽ���b�̴̳�Y�����M�ͣ����㶮Ƕ���rֵ1000Ԫ������ARMϵ��ҕ�l������̳����r���t���������¡�ARM�n���n�Ì�䛾��A��ҕ�l���M�I(l��ng)ȡ����(n��i)��Դ linux��(n��i)�˼����c���Ƽ��g(sh��)�A���ԌW(xu��)��(x��)���������cAdam��(y��u)�����ı��^һ���x�����ډ��s��֪�Ĕ�(sh��)��(j��)���s���g(sh��)Ƕ��ʽϵ�y(t��ng)�еĶ��̎�����c����Ӌ��Ƕ��ʽϵ�y(t��ng)�е�Ӳ�����ܼ��������Ɍ����W(w��ng)�j(lu��)��GAN�����g(sh��)����(w��n)�����cģʽ����Ƕ��ʽϵ�y(t��ng)�еĴ��a��(y��u)���c���s���g(sh��)����Ƕ��ʽϵ�y(t��ng)�ĄӑB(t��i)늉��l���{(di��o)����DVFS������ע�����C��:Transformerģ�͵��������

