
 ����ȌW����ʹ��Dropout���g�ĄәC������η�ֹ�^�M��
�r�g��2025-01-17 ��Դ���A���hҊ
����ȌW����ʹ��Dropout���g�ĄәC������η�ֹ�^�M��
�r�g��2025-01-17 ��Դ���A���hҊ
һ��ʲô���^�M��?
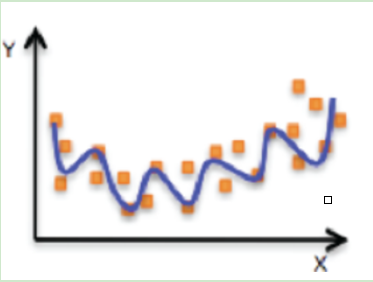
�^�M�ϣ�overfitting����ָ��ȌW�����x���ģ���������ą����^�ࣨ��ģ�������ܴ������ڳ��F�@һģ�͌���֪�����A�y�úܺã�����δ֪�����A�y�úܲ�ĬF��
�D���^�M�ϵ����ӣ������ܺõĔM���˘ӱ������ӱ��dz��دB��ͬ�Әӱ��е�������Ҳ���M���ˣ���������Ӱ���ģ��Ӗ����
����ʲô��Dropout��
Srivastava�ȴ�ţ��2014���Փ�ġ�Dropout: A Simple Way to Prevent Neural Networks from Overfitting�������Dropout���t����
Dropout�ı�ʾÿ��Ӗ���r�S�C����һ������Ԫ���@Щ��Ԫdropped-out�ˡ��Q��Ԓ�v���@Щ��dropped-out����Ԫ����������r��ǰ��Ԫ����ֵ�ஔ�ڞ�0��������ӵ���Ԫ��Ӱ푱����ԣ���������rҲ������������ء�
����Dropout���g�ĄәC��
Dropout���g����Ҫ�әC�Ƿ�ֹ�W�j��Ӗ���^���У�Ӗ�������^�M�ϡ�Dropoutͨ�^�S�C�G��һ������Ԫ��ʹ��ģ����ÿ�ε�����ʹ�ò�ͬ����Ԫ�M���M��Ӌ�㣬�Ķ��p��ģ�͌�ijЩ��Ԫ����ه������ģ�͵ķ���������
�ġ�Dropout��η�ֹ�^�M�ϣ�
1. �p����Ԫ֮�g�����ه������ÿ�ε��������S�C�G��һЩ��Ԫ�����ԾW�j�����^����ه�κ�һ���ض�����Ԫ���@ʹ�þW�j�܉�W��������������������������ʾ��
2. ����ģ�͵ķ������������� dropout �������S�C�ԣ�����ÿ�ε�������Ӗ��һ�����в�ͬ�ľW�j��߀�W����������m���µġ�δҊ�^�Ĕ������@���������ģ�͵ķ���������
3. ģ�M���ɌW����Dropout ���Կ�����һ�N���ɌW��������ÿ�ε�������Ӗ��һ�����в�ͬ�ľW�j���@Щ�W�j���Կ����nj�ԭʼ�W�j�IJ�ͬ“�y”���ڜyԇ�A�Σ��҂����H������ƽ������“�y”�ĽY�����@ͨ���Ȇ�һ�W�j�ĽY��Ҫ�á�
 �n�̷������A���hҊ��NXP�Ƴ�i.MX8M Plus�_�l�c���`�n�̷���������HarmonyOSϵ�y�����W�_�l�����n�̣��n�̷�����HaaS EDU K1�_�l�̳̣����n��ҕ�l��Դ�a���°�C�Z�Ծ���֮�����Z��ҕ�l�̳��ذ�ٛ�ͣ�Ƕ��ʽ���rֵ2000Ԫ��Ƕ��ʽ���b�̴̳�Y�����M�ͣ����㶮Ƕ���rֵ1000Ԫ������ARMϵ��ҕ�l������̳����r���t���������¡�ARM�n���n�Ì�䛾��A��ҕ�l���M�Iȡ���Ⱥ�Դ
�n�̷������A���hҊ��NXP�Ƴ�i.MX8M Plus�_�l�c���`�n�̷���������HarmonyOSϵ�y�����W�_�l�����n�̣��n�̷�����HaaS EDU K1�_�l�̳̣����n��ҕ�l��Դ�a���°�C�Z�Ծ���֮�����Z��ҕ�l�̳��ذ�ٛ�ͣ�Ƕ��ʽ���rֵ2000Ԫ��Ƕ��ʽ���b�̴̳�Y�����M�ͣ����㶮Ƕ���rֵ1000Ԫ������ARMϵ��ҕ�l������̳����r���t���������¡�ARM�n���n�Ì�䛾��A��ҕ�l���M�Iȡ���Ⱥ�Դ

