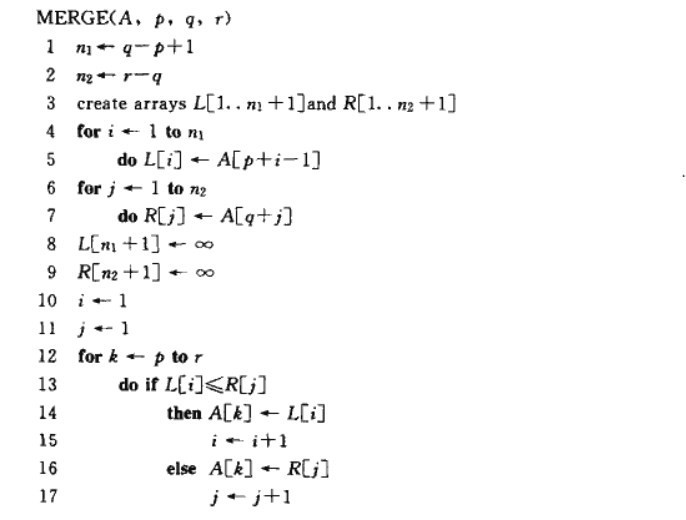�㷨���A��һ��
�r�g��2016-12-14���ߣ��A���hҊ
���� �҂����Ҫ�о����� �҂�֮ǰ�ѽ��W�^��������ð�����������҂���Bһ�²�������ͺϲ����� ��������ęC�ƺʹ��ƕr�������е���������ࡣ���Ƶĕr����Ҫ���������Ʋ��뵽����һ�����е����_��λ���ϡ�����Ҫ�ҵ��@���Ƶ�λ�ã��҂���Ҫ�����c����ÿ���Ə��ҵ����M�б��^���oՓ�Εr�������е��ƶ����ź���ġ� �@���㷨�У����е�Ԫ�ض���ԭ������sorted in place��������ζ���@Щ���־����ڔ��M��������������ġ� �㷨���£� �δ��a�� ���a��c�Z�Ԍ��F����
//a ��һ�����M��size_a���@�����M��Ԫ���� ���������㷨�ĕr�g���s����O(n 2 ) ����Ȼ�㷨�Ĉ����ٶȣ���n�Ĵ�С��ݔ��Ҏģ���Լ��ӱ��ĽY�����Pϵ�����]�ĵ���r������ݔ���n�������������У��˕r���������㷨���S��n�������\��r�g�����L�c n 2 ͬ�������� 2.���η����� �ֽ⣨divide�����vԭ�І��}�ֽ�ɞ�һϵ���ӆ��}�� �ϲ����� merge�^�̵Ĵ��r��O(n)������n = r - p + 1�Ǵ��ϲ���Ԫ������ �����ܙz��ɂ��Ӕ��M�Ƿ��ǿգ����뷨����ÿһ�����M�ײ���һ�����ڱ�����������������ֵ�����ں������a��
���w���f��merge�^�����@�ӹ����ģ���һ��Ӌ���Ӕ��Ma[p...q]���L��n1,�ڶ���Ӌ���Ӕ��Ma[q+1...r]���L��n2.�ڵ������У������˔��ML��R���L�ȸ�λn1 +1,n2 + 1.���ĵ��������е�forѭ�h���Ӕ��Ma[p...q]���Ƶ�L[1....n1]��ȥ�� �������������е�forѭ�h���Ӕ��Ma[q+1...r]���Ƶ�R[1....n2]��ȥ���ڰ˾����v�ڱ�����L��R��ĩβ����ʮ����ʮ���У��Ǻϲ��ľ��w�^�̡�ͨ�^���^�������Ӕ��M���Տ�С����ķ�ʽ�ϲ������딵�MA�С� c�Z������������ʾ void merge( int * a, int p, int q, int r){ �ϲ�merge�^�̾Ϳ�������ϲ������е�һ���ӳ����ʹ�á��δ��a���£�
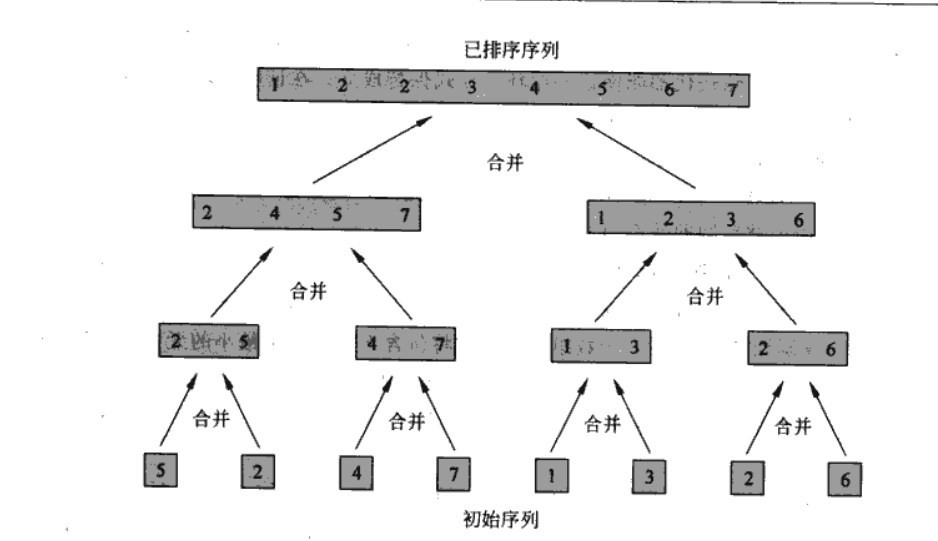
c�Z�������^�̞飺 void merge_sort( int * a, int p, int r){ �ϲ�����ľ��w�Dʾ��
�P�ڷ��η�����ĺ�Ҫ������
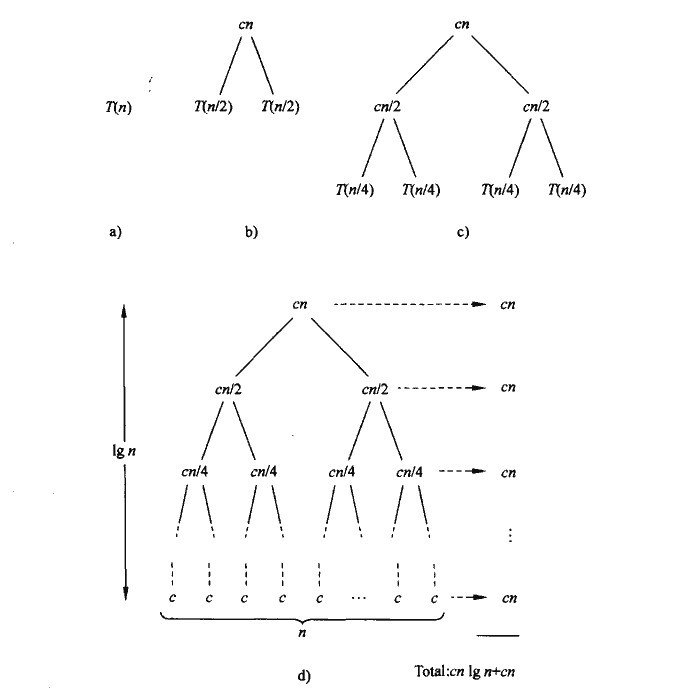
�҂���һ��Ҏģ��n�Ć��}����ֳ�n��Ҏģ��1���ӆ��}����ֵ��^�̽��v�� lg n + 1�ӣ��ںϲ��r��ÿһ�ӵĆ��}Ҏģ��n���t�����r��O (n * lg n + n ) �����Ե��A헺ͳ���헣���˺ϲ����ĕr�g���s�Ȟ�O(n lg n )�� �������Bһ�¶�����Ϳ����������ϵ��������������DZ��^����Ҳ�����f������ͨ�^�����MԪ�ر��^�팍�F�����^�������ИO�ģ��ĉĵ�ݔ����r�����^���ĕr�g���s���� O(n lg n )���҂���B�ĺϲ������Լ����������ǝu�M���ı��^����ʽ���҂�߀����B����ͻ�Ʊ��^����O������ʽ����Ӌ������
���P�YӍ
�l���uՓ
|