 Hadoop 簡介以及其生態系統概況
時間:2018-09-27 來源:未知
Hadoop 簡介以及其生態系統概況
時間:2018-09-27 來源:未知
Hadoop起源:hadoop的創始者是Doug Cutting,起源于Nutch項目,該項目是作者嘗試構建的一個開源的Web搜索引擎。起初該項目遇到了阻礙,因為始終無法將計算分配給多臺計算機。谷歌發表的關于GFS和MapReduce相關的論文給了作者啟發,終讓Nutch可以在多臺計算機上穩定的運行;后來雅虎對這項技術產生了很大的興趣,并組建了團隊開發,從Nutch中剝離出分布式計算模塊命名為“Hadoop”。終Hadoop在雅虎的幫助下能夠真正的處理海量的Web數據。
Hadoop集群是一種分布式的計算平臺,用來處理海量數據,它的兩大核心組件分別是HDSF文件系統和分布式計算處理框架mapreduce。HDFS是分布式存儲系統,其下的兩個子項目分別是namenode和datanode;namenode管理著文件系統的命名空間包括元數據和datanode上數據塊的位置,datanode在本地保存著真實的數據。它們都分別運行在獨立的節點上。Mapreduce的兩大子項目分別是jobtracker和tasktracker,jobtracker負責管理資源和分配任務,tasktracker負責執行來自jobtracker的任務。
Hadoop1升級成hadoop2后,為解決原來HDFS的namenode的單點故障問題,于是有了HA集群的出現;為解決原來mapreduce的jobtracker的單點故障以及負擔過重的問題,于是有了mapreduce2也就是YARN的出現。
HA集群我們采取了QJM的方式進行;每個節點上安裝hadoop,java JDK,子節點(datanode)安裝zookeeper搭建journalnode集群(該集群數量必須是單數);HA結構具有高可用性, ACtive namenode和standby namenode之間元數據是同步的;ACtive namenode 每次完成操作后,生成edits log,會將edits log通過ZKFC發送給journalnode集群的多數派(當journalnode集群的大多數節點拿到edits log即視為成功),datanode拿到數據會將數據發送給standby namenode,同時datanode還會將自己的數據塊的位置信息報告給standby namenode。client向active namenode發出請求,當active namenode無回應時,active會直接向standby namenode發出請求,此時standby namenode會轉變為active namenode。
YARN是hadoop2里mapreduce的別稱;它將一版本里的jobtracker的工作分為了兩部分:ResourceManager 和AppMaster 分別管理mapreduce的資源和工作周期。除此之外,yarn同樣解決了jobtracker的單點故障問題。
Hadoop作為一個分布式處理大數據的平臺。它的內部機制挺復雜的,但是如果是僅僅作為使用者,我們只需要弄清楚它的工作機制,它的功能以及如何使用就行。Hadoop與其他的Hadoop項目比如說:Ambari,Hive,Hbase,Pig,Spark,zookeeper......一起組成hadoop生態圈,共同完成對大數據的處理和分析。Hadoop和其他一些大數據平臺一起被稱為大數據技術。
Hadoop 的核心子項目是 HDFS 和 Mapreduce,hadoop2.0 還包括 YARN資源管理器。圖1.1為 hadoop 的生態系統。
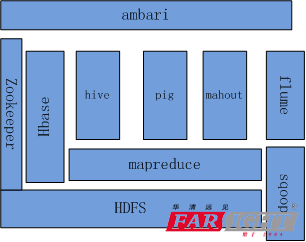
圖1.1 hadoop 的生態系統
(1)HDFS:
是Hadoop體系中數據存儲管理的基礎。它是一個高度容錯的系統,能檢測和應對硬件故障,用于在低成本的通用硬件上運行。HDFS 簡化了文件的一致性模型,通過流式數據訪問,提供高吞吐量應用程序數據訪問功能,適合帶有大型數據集的應用程序
(2)MapReduce
是一種計算模型,用以進行大數據量的計算。其中 Map 對數據集上的獨立元素進行指定的操作,生成鍵-值對形式中間結果。Reduce 則對中間結果中相同“鍵”的所有“值”進行規約,以得到終結果。MapReduce 這樣的功能劃分,非常適合在大量計算機組成的分布式并行環境里進行數據處理。
(3)Hive:
數據倉庫基礎設施,提供數據匯總和特定查詢。這個系統支持用戶進行有效的查詢,并實時得到返回結果,定義了一種類似 SQL 的查詢語言(HQL),將 SQL 轉化為 MapReduce 任務在 Hadoop 上執行。通常用于離線分析。
(4)Spark
Spark 是提供大數據集上快速進行數據分析的計算引擎。它建立在HDFS 之上,卻繞過了 MapReduce 使用自己的數據處理框架。Spark 常用于實時查詢、流處理、迭代算法、復雜操作運算和機器學習。
(5)Ambari:
Ambari 用來協助管理 Hadoop。它提供對 Hadoop 生態系統中許多工具的支持,包括 Hive、HBase、Pig、 Spooq 和 ZooKeeper。這個工具提供集群管理儀表盤,可以跟蹤集群運行狀態,幫助診斷性能問題。
(4)Pig:
Pig 是一個集成高級查詢語言的平臺,可以用來處理大數據集。
(5)HBase:
HBase 是一個非關系型數據庫管理系統,以zookeeper做協同服務,運行在 HDFS 之上。它用來處理大數據工程中稀疏數據集。是一個針對結構化數據的可伸縮、高可靠、高性能、分布式和面向列的動態模式數據庫。和傳統關系數據庫不同,HBase 采用了 BigTable 的數據模型:增強的稀疏排序映射表(Key/Value),其中,鍵由行關鍵字、列關鍵字和時間戳構成。HBase 提供了對大規模數據的隨機、實時讀寫訪問,同時,HBase 中保存的數據可以使用 MapReduce 來處理,它將數據存儲和并行計算完美地結合在一起。數據模型:Schema-->Table-->Column Family-->Column-->RowKey-->TimeStamp-->Value。
(6)Zookeeper
解決分布式環境下的數據管理問題:統一命名,狀態同步,集群管理,配置同步等。
(7)Sqoop(數據同步工具)
Sqoop 是 SQL-to-Hadoop 的縮寫,主要用于傳統數據庫和 Hadoop 之前傳輸數據。數據的導入和導出本質上是 Mapreduce 程序,充分利用了 MR 的并行化和容錯性。
(8)Pig:
基于 Hadoop 的數據流系統設計動機是提供一種基于 MapReduce 的 ad-hoc(計算在 query 時發生)數據分析工具定義了一種數據流語言—Pig Latin,將腳本轉換為 MapReduce 任務在 Hadoop 上執行。通常用于進行離線分析。
(9)Mahout (數據挖掘算法庫)
Mahout 起源于 2008 年,初是 Apache Lucent 的子項目,它在極短的時間內取得了長足的發展,現在是 Apache 的頂級項目。Mahout 的主要目標是創建一些可擴展的機器學習領域經典算法的實現,旨在幫助開發人員更加方便快捷地創建智能應用程序。Mahout 現在已經包含了聚類、分類、推薦引擎(協同過濾)和頻繁集挖掘等廣泛使用的數據挖掘方法。除了算法,Mahout 還包含數據的輸入/輸出工具、與其他存儲系統(如數據庫、MongoDB 或 Cassandra)集成等數據挖掘支持架構。
(10)Flume(日志收集工具)
Cloudera 開源的日志收集系統,具有分布式、高可靠、高容錯、易于定制和擴展的特點。它將數據從產生、傳輸、處理并終寫入目標的路徑的過程抽象為數據流,在具體的數據流中,數據源支持在 Flume中定制數據發送方,從而支持收集各種不同協議數據。同時, Flume數據流提供對日志數據進行簡單處理的能力,如過濾、格式轉換等。此外,Flume 還具有能夠將日志寫往各種數據目標(可定制)的能力。總的來說,Flume 是一個可擴展、適合復雜環境的海量日志收集系統。
(11)資源管理器的簡單介紹(YARN)
隨著互聯網的高速發展,基于數據密集型應用的計算框架不斷出現,從支持離線處理的
MapReduce,到支持在線處理的 Storm,從迭代式計算框架 Spark 到流式處理框架 S4,…,各種框架誕生于不同的公司或者實驗室,它們各有所長,各自解決了某一類應用問題。而在大部分互聯網公司中,這幾種框架可能都會采用,比如對于搜索引擎公司,可能的技術方案如下:網頁建索引采用 MapReduce 框架,自然語言處理/數據挖掘采用 Spark(網頁 PageRank計算,聚類分類算法等),對性能要求很高的數據挖掘算法用 MPI 等。考慮到資源利用率,運維成本,數據共享等因素,公司一般希望將所有這些框架部署到一個公共的集群中,讓它們共享集群的資源,并對資源進行統一使用,這樣,便誕生了資源統一管理與調度平臺,典型代表是YARN。
hadoop其他的一些開源組件:
1) cloudera impala:
impala 是由 Cloudera 開發,一個開源的 Massively Parallel Processing(MPP)查詢引
擎 。與 Hive 相同的元數據、SQL 語法、ODBC 驅動程序和用戶接口(Hue Beeswax),可以直接在 HDFS 或 HBase 上提供快速、交互式 SQL 查詢。Impala 是在 Dremel 的啟發下開發的,第一個版本發布于 2012 年末。Impala 不再使用緩慢的 Hive+MapReduce 批處理,而是通過與商用并行關系數據庫中類似的分布式查詢引擎(由 Query Planner、Query Coordinator 和 Query Exec Engine 三部分組成),可以直接從 HDFS 或者 HBase 中用 SELECT、JOIN 和統計函數查詢數據,從而大大降低了延遲。
2)spark:
Spark 是個開源的數據分析集群計算框架,初由加州大學伯克利分校 AMPLab 開發,建立于 HDFS 之上。Spark 與 Hadoop 一樣,用于構建大規模、低延時的數據分析應用。Spark 采用 Scala 語言實現,使用 Scala 作為應用框架。Spark 采用基于內存的分布式數據集,優化了迭代式的工作負載以及交互式查詢。與Hadoop不同的是,Spark和Scala緊密集成,Scala 像管理本地collective對象那樣管理分布式數據集。Spark 支持分布式數據集上的迭代式任務,實際上可以在Hadoop 文件系統上與Hadoop一起運行(通過 YARN、Mesos 等實現)。
3) storm
Storm 是一個分布式的、容錯的實時計算系統,由BackType開發,后被Twitter捕獲。Storm 屬于流處理平臺,多用于實時計算并更新數據庫。Storm 也可被用于“連續計算”(continuous computation),對數據流做連續查詢,在計算時就將結果以流的形式輸出給用戶。它還可被用于“分布式 RPC”,以并行的方式運行昂貴的運算。存儲和并行計算完美地結合在一起。



华清图书馆
0元电子书,限时免费申领10本华清图书PDF版
扫码关注华清远见公众号



