�����c�����㷨
�r�g��2018-09-26 ��Դ��δ֪
�����c�����㷨
�r�g��2018-09-26 ��Դ��δ֪
һ������Ļ��������c���
1������Ķ��x
���O����n��ӛ䛵����О�{r1,r2,……rn}�������������P�I�ַքe��{k1,k2,……kn}����_��һ�N���У�ʹ���P�I�֝M��k1<=k2<=……<=km(���f�p)��k1>=k2>=……>=km(���f��)�Pϵ����ʹ�����гɞ�һ�����P�I�����������{r1,r2,……,rm}���@�ӵIJ����ͷQ������
������������P�I��֮�g�Ĵ�С�Pϵ����ô������ͬһ��ӛ䛼��ϣ�ᘌ���ͬ���P�I���M�������Եõ���ͬ�����С�
2������ķ����ԡ�
���O������ǰ����ki=kj(1<=i<=n��1<=j<=n��i������j)����������ǰ��������riλ����rj(��i
����������
��̖ ���� ����
1 Li 750
2 Liu 730
3 Zhou 738
4 Han 750
�˕r�҂���������������õ�
1 Li 750
4 Han 750
2 Zhou 738
3 Liu 730
�@�������㷨���Ƿ����ġ�������õ�
4 Han 750
1 Li 750
2 Zhou 738
3 Liu 730
�t�@�ӵ������㷨���Dz������ġ�
���ڶ����P�I������r�������һ�M�P�I�֕��õ��������ĽY�����t�҂����J��������㷨�Dz������ġ�
3�������㷨�ķ��
1)������λ�÷��
���������^���д��Ŕ����Ƿ�ȫ���������ڃȴ��У�����֞飺�������������
�����������^���У����Ŕ���ȫ���������ڃȴ��С�
�����������^���У���ӛ�̫�࣬����ͬ�r���ڃȴ��У����������^������Ҫ�ڃ����֮�g��ν��Q���������M�С�
�҂��@��ֻӑՓ�������㷨�����ڃ�������f�������㷨��������Ҫ��3������Ӱ푣�
���r�g����
�����ǔ���̎��r�������еIJ������������ں��Ĵ��a���֣���������㷨�ĕr�g�_�N�Ǻ�����Éĵ���Ҫ��־���������У���Ҫ�漰���ɷN���������^�c�Ƅӡ���Ч�ʵ������㷨��ԓ�Ǿ��бM�����ٵ��P�I�ֱ��^�Δ��ͱM�����ٵĔ����ƄӴΔ���
���o�����g
�u�r�����㷨����һ����Ҫ�˜��Lj����㷨����Ҫ���o�����g���o���惦���g�dz��˴�Ŵ�������ռ�õĴ惦���g֮�⣬�����㷨����Ҫ���~��惦���g��
���㷨�ď��s��
�^�ڏ��s���㷨��Ӱ����������ܡ�
2)������������
���������^���н����IJ������҂�������֞飺���������Q�����x������͚w������
3)���㷨�ď��s�Է��
���������㷨�ď��s�Է���ɷ֞麆�������㷨���M�����㷨��
���������㷨��ð������ֱ���x������ֱ�Ӳ�������
���M�����㷨��Shell�������w������������
//ע���������漰���Ĵ��aԔҊ���
��������
�oՓ�W���ķN�����Z�ԣ����W����ѭ�h�c���M�ȸ���ĕr��ͨ������Bһ�N�����㷨���������ӻ��������@�N�����㷨ͨ������ð������
1�����ε�ð������
ð������(Bubble Sort)��һ�N���Q�������Ļ���˼���ǣ��Ƀɱ��^����ӛ䛵��P�I�֣��������t���Q��ֱ���]�з����ֹ��
�������^���У��^С�Ĕ���(���^��Ĕ���)����ͬˮ�µĚ���һ����������ˮ�棬ð������������ʹ˶�����
//���aҊ���
2������1
ð�������Ƿ�����M�Ѓ�����?���ǿ϶��ġ�
ԇ�룬����������ǻ��������(����2,1,3,4,5,6,7,8,9,10�����˵�һ�͵ڶ����P�I�ֲ�ͬ����Ҫ���Q�⣬���������P�I�ֶ��ѽ����˕r�҂�ֻ�轻�Q�@�ɂ����ּ��ɣ����o�茢ð��������е��ס�
�҂������O��һ����־λflag��������ָʾһ��ð��������к��Ƿ��Д������Q�����һ�������]�Д������Q���҂��Ϳ����J�锵���ѽ����o�����^�m���к���Ĺ����ˡ�
//���aҊ���
���a�Ąӵ��P�I���������ѭ�hfor()�ĽY���l���У������ˌ�flag�Ƿ���true���Дࡣ�@�ӵĸ��M�ܱ��┵�����������r�����o���x��ѭ�h�Д࣬�Ķ�����Ч�ʡ�
3������2
����һ���Ƕȁ��룬һ��ѭ�h������ǰ���赽��Ȼ���ُ�ǰ���赽��……Ҳ�����f��“���^”����һ�������Ƅ�һ���P�I��ʹ����������҂�����“���^”�Ƅӻر��^�r��Ҳ���Ƅ�һ���P�I�֣���ô���ஔ��һ�Β���һ�������ƄӃɂ��P�I�֣��������������Ч�ʡ�
//���aҊ���
����ֱ���x������
ð�������ǻ��ڱ��^�ͽ��Q���������㷨˼����Dz��ཻ�Q��ͨ�^���Q��ɽK����ֱ���x������t�ǻ����x����������㷨˼����ÿ���x�����Ŕ������P�I���д�(��С)�Ĕ��������i��ӛ䛡�
1��ֱ���x�������㷨
�x�������㷨(Selection Sort)����ͨ�^n-i���P�I�ֱ��^����n-i+1��������ÿ�����x���P�I��С(���)�Ĕ������͵�i(1<=i<=n)���������Q֮��
//���aҊ���
ע����a�е�min���@�������^����С�������ˡ�
�������ρ��f���x�������ԃ���ð������
�ġ�ֱ�Ӳ�������
��������҂������^���Α���ô�����ֵē�������������?һ����r�£������x��һ���ƣ����������ڱ�����ͱ���С�ăɏ���֮�g���@���҂��������Ƶķ�������ֱ�Ӳ�������
1��ֱ�Ӳ��������㷨
ֱ�Ӳ��������㷨(Straight Insertion Sort)�Ļ��������nj�һ���������뵽һ���ѽ��ź����������У��Ķ��õ�һ���µ���������؏��@���^�̣�ֱ�����Д�������
//���aҊ���
��Ҫע����ǣ�ֱ�Ӳ���������Ҫһ���ѽ��������������“����”�����a�У��x�^r[0]�cr[1]������ʣ�������ǰ����Ҫ�Д�r[0]�cr[1]���Pϵ���C��������������ԇLԇʡ�Ե��@һ�����^�������ă��ݡ�
�������ρ��f��ֱ�Ӳ��������ԃ���ð������
�塢��������
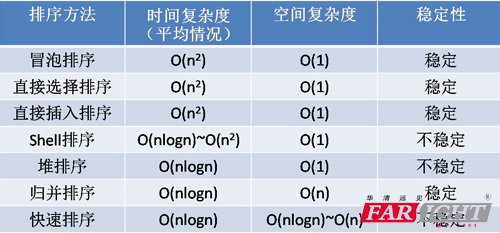
�����н�B�ĵ�ð�������x������ֱ�Ӳ�����������M�汾�������ں��������㷨����������ĕr�g���s�ȶ���O(n^2)�������M�����㷨(Shell�������w������������)�ĕr�g���s�ȶ���O(nlog2n)�������졣���@���҂���Ҫ�W����������
1�����������㷨
���������㷨���ɈD�`���@����Tony Hoare��1962���OӋ���������Q��“20���oʮ���㷨”֮һ��
���������ஔ��ð����������������߶����ڽ��Q�����
��������(Quick Sort)�Ļ���˼���ǣ�ͨ�^һ�������Ŕ����ָ�ɪ����ăɲ��֣�����һ���ֵ��P�I�ֶ�����һ���ֵ��P�I��С��֮���@�ɲ��ַքe�M�����K�_�����w����
���������㷨�����������ǣ�
1)�O�Ãɂ�׃��i��j�������_ʼ�ĕr��i=0��j=N-1;
2)�Ե�һ�����MԪ�������P�I�������xֵ�okey����key=A[0];
3)��j�_ʼ��ǰ���������ɺ��_ʼ��ǰ����(j--)���ҵ���һ��С��key��ֵA[j]����A[j]��A[i]���Q;
4)��i�_ʼ�������������ǰ�_ʼ�������(i++)���ҵ���һ������key��A[i]����A[i]��A[j]���Q;
5)�؏͵�3��4����ֱ��i=j;�˕r��ѭ�h�Y������keyֵ�xֵ��i(��j)��λ�á�
6)�f�w�������MA[]��keyֵ�����벿�֡�
7)�f�w�������MA[]��keyֵ�ҵ��Ұ벿�֡�
//���aҊ���
2�����������㷨�ă�ȱ�c
���������㷨֮���Խ�“����”������ζ��Ŀǰ�A�Λ]�����ҵ����������@���㷨�������㷨�����ijһ�������ҵ��˸��õ������㷨��“����”�͕��������������^�������ֹ��Tony Hoare�l���������㷨���^������������w�����ϣ���Ȼ�������㷨�е����ߡ�
���^���������㷨����ȱ�ݣ����������㷨�mȻ��������ʮ�����L���������L���������r�M�������ڔ��������r�����������cð��������������r�g�ϵă��ݣ�ֻ�Д�������r������������ܰl�]�����ă��ݡ�����҂��ڌ������M������r������������̫�࣬�����x��ʹ�����N���������㷨(ð�������x������ֱ�Ӳ�������);�����������҂�����Ҫ�x���������
���1���������㷨���a���F(C�Z��)
#include
#include
#define MAXSIZE 10
typedef struct
{
int r[MAXSIZE];//�惦������
int length;//ӛ��������L��
}Sqlist;
void swap(Sqlist *L,int i,int j)//���Q��������
{
int temp = L->r[i];
L->r[i] = L->r[j];
L->r[j] = temp;
}
void print(Sqlist *L)//��ӡ��������
{
int i;
for(i=0;i
printf("%d ",L->r[i]);
printf("\n");
}
void BubbleSort(Sqlist *L)//����
{
int i,j;
for(i=0;i
{
for(j=L->length-1;j>=i;j--)
{
if(L->r[j]>L->r[j+1])
swap(L,j,j+1);
}
}
}
void BubbleSort2(Sqlist *L)//ð��������M��1�����Ә�־λ
{
int i,j;
int flag = 1;
for(i=0;i
{
flag = 0;
for(j=L->length-1;j>=i;j--)
{
if(L->r[j]>L->r[j+1])
{
swap(L,j,j+1);
flag = 1;
}
}
}
}
void BubbleSort3(Sqlist *L)//ð��������M��2���p���ƄӔ���(�uβ������)
{
int i,j;
for(i=0;i
{
for(j=i;j
{
if(L->r[j]>L->r[j+1])
swap(L,j,j+1);
}
for(j=L->length-1-(i+1);j>i;j--)
{
if(L->r[j]
swap(L,j-1,j);
}
}
}
void SelectSort(Sqlist *L)//ֱ���x������
{
int i,j,min;//min�Ǯ���ѭ�h��Сֵ����
for(i=0;i
{
min=i;
for(j=i+1;j<=L->length;j++)
{
if(L->r[min]>L->r[j])
min=j;
}
if(i!=min)
swap(L,i,min);
}
}
void InsertSort(Sqlist *L)//ֱ�Ӳ�������
{
int i,j,tmp;
if(L->r[0]>L->r[1])//���ȱ��Cǰ2��Ԫ�������@�Ӻ��mԪ�ز��ܲ���
swap(L,0,1);
for(i=2;i<=L->length;i++)//����L->r[i]Ԫ��
{
if(L->r[i]
{
tmp=L->r[i];
for(j=i-1;L->r[j]>tmp;j--)//�����д���L->r[i]Ԫ�ض����ƣ��ճ�λ��
L->r[j+1]=L->r[j];
L->r[j+1]=tmp;//�������_�
}
}
}
void QSort1(Sqlist *L,int left,int right)//��������
{
int i=left,j=right;
if(left>=right)
return;
int key = L->r[left];
while(i
{
while(L->r[j]>=key && i
j--;
L->r[i]=L->r[j];
while(L->r[i]<=key && i
i++;
L->r[j]=L->r[i];
}
L->r[i]=key;
QSort1(L,left,i-1);
QSort1(L,i+1,right);
}
/*���������㷨�ڶ��N����*/
int Partition(Sqlist *L,int low,int high)
{
int pivotkey,tmp;
pivotkey=L->r[low];
tmp=pivotkey;
while(low
{
while(low
high--;
L->r[low]=L->r[high];
while(low
low++;
L->r[high]=L->r[low];
}
L->r[low]=tmp;
return low;
}
void QSort2(Sqlist *L,int low,int high)
{
int pivot;
if(low
{
pivot = Partition(L,low,high);
QSort2(L,low,pivot-1);
QSort2(L,pivot+1,high);
}
}
/*���������㷨�ڶ��N����end*/
int main()
{
Sqlist data;
data.r[0]=9;data.r[1]=1;data.r[2]=5;data.r[3]=8;data.r[4]=3;data.r[5]=7;data.r[6]=4;data.r[7]=6;data.r[8]=2;data.r[9]=10;
data.length=sizeof(data.r)/sizeof(data.r[0]);
//BubbleSort(&data);
//BubbleSort2(&data);
//BubbleSort3(&data);
//SelectSort(&data);
//InsertSort(&data);
//QSort1(&data,0,data.length-1);
//QSort2(&data,0,data.length-1);
print(&data);
return 0;
}
���2���������㷨�r�g���s���c���g���s�Ȍ���