Linux�¿ƴ�Ӎ�w�Z���R�eȫ�濂�Y
�r�g��2018-05-14 ��Դ��δ֪
Linux�¿ƴ�Ӎ�w�Z���R�eȫ�濂�Y
�r�g��2018-05-14 ��Դ��δ֪
�����҂���Ҫ�ľ���Linux�µ�SDK�����d���������ڿƴ�Ӎ�w�ĹپW//www.xfyun.cn/ע�ԣ��x���҂����Z���R�e�Ĺ���������Linux SDK���d������������Linux_iat1166_tts_online1166_5ad417ef.zip �ĉ��s����Ȼ��≺�s���£�

binĿ��������҂������ɵĿɈ��е��ļ�;
docĿ����҂���api�����ӿڵą������ęn;
includeĿ��������҂��ľ��g��ĿɈ����ļ��õ����^�ļ�;
libs���҂��ij����õ��Ď�;
samplesĿ������Ǻ��ε��Z���ϳɡ��Z���R�e���Z���D���ֵ�demo;
�ГQ���҂���samples�����iat_record_sample���Z���R�e��demo��source 32bit_make.sh,���҂���binĿ������ɿɈ����ļ�iat_record_sample

���Lj��Еr���Ferror while loading shared libraries: libmsc.so���e�`

uame -a ����uname -p�鿴�҂���ubuntu̓�M�C��32λ߀��64λ��

�ٌ����Č��҂���libsĿ��µĎ쿽ؐ��/usr/libs����
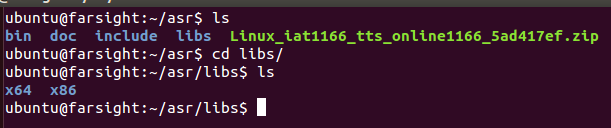
���\���҂���bin��������ɵ�iat_record_sample�Ɉ����ļ�
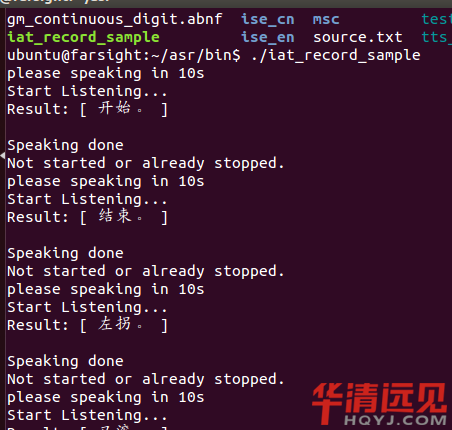
�����҂�demoֻ���Ԍ��Fһ���R�e�҂��Z���������҂��Ĵ��a�����һֱ�ȴ�ݔ�룬
����ÿ�εȴ�ݔ��ĕr�g��10s犣�Ȼ����Կ����҂��ı��ص����аl�������Ԍ��F�҂����Z���D�Q�錦�����ı�
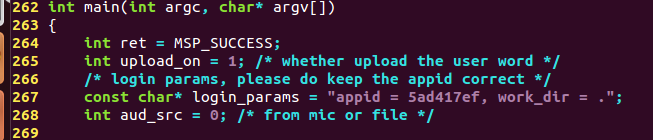
�҂���main������login_params����c�҂��Լ���Ո��SDK��appid��ͬ����Ȼ�ƶ��ھ��rSDK�cappid��һ�o��ʹ���Z���Ĺ���
���ˌ��Fһֱݔ�룬���҂���while(1)���{��demo_mic������demo_mic��sr_init��sr_start_listening��sr_stop_listening���F�҂����Z�����ļ�����ʼ�ͽY��

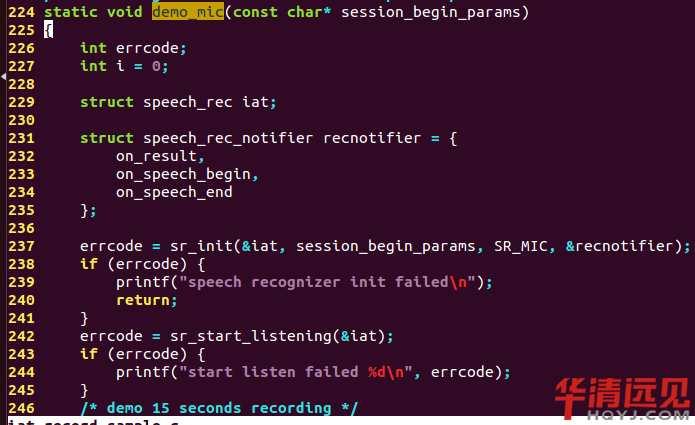
sr_start_listening�����е�create_record��open_record��start_record��stop_record��close_record���P�������F�҂��������Ą��������_��ֹͣ���P�]